1. Submit
Send an AI workload
Use the CLI, API, portal, or an AI agent to submit inference, training, image generation, batch scripts, or containerized jobs.
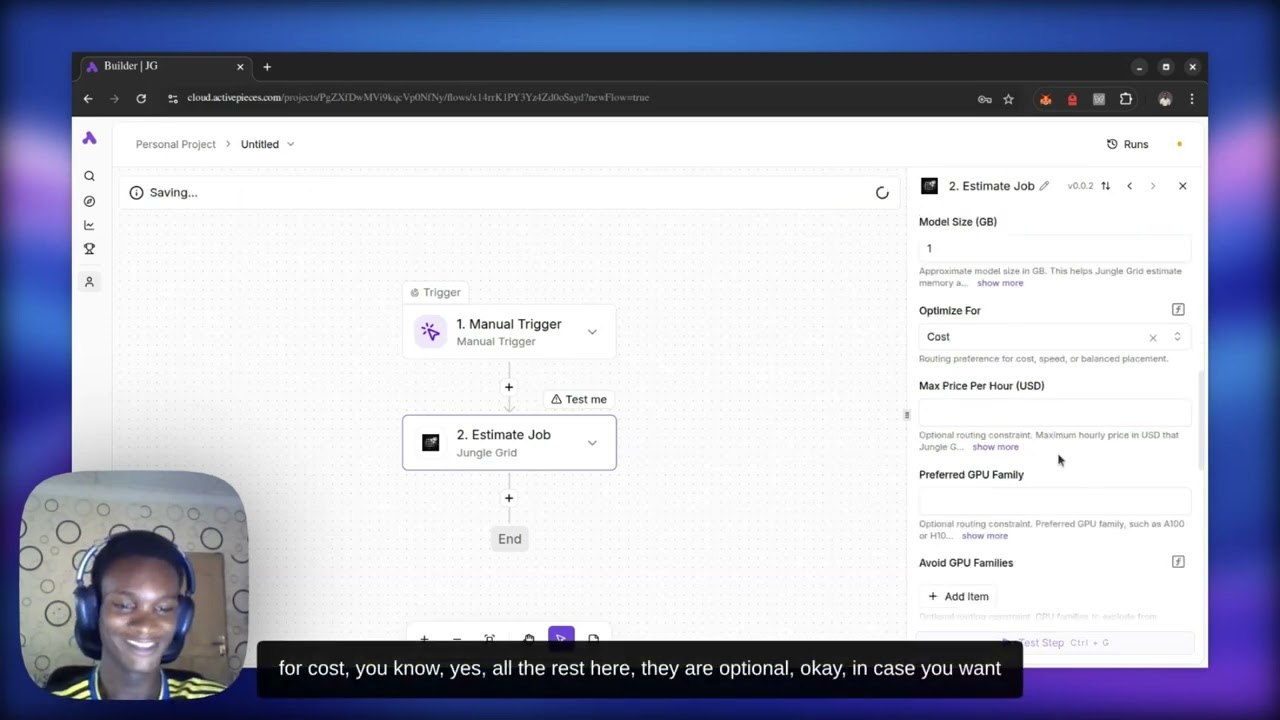
Jungle Grid is the execution layer between your AI workload and the GPU capacity needed to run it. Submit a container, model task, or agent job; Jungle Grid picks suitable hardware, starts the run, streams logs, and keeps the result visible.
Submit a workload
npx @jungle-grid/cli@latest submit \
--workload inference \
--model-size 7 \
--image pytorch/pytorch:2.4.0-cuda12.1-cudnn9-runtime \
--name chat-infernpx @jungle-grid/cli@latest status <job-id>What Jungle Grid is
Jungle Grid lets you run model inference, fine-tuning, image generation, batch processing, and containerized AI tasks without renting GPU servers, choosing cloud providers, or wiring up failover yourself.
It is not a notebook and not a raw cloud console. It is the execution layer between your AI app or workflow and the GPU capacity needed to run it.
Use the CLI, API, portal, or an AI agent to submit inference, training, image generation, batch scripts, or containerized jobs.
It checks model size, VRAM fit, price, queue pressure, provider health, and reliability before placing the job.
You watch status and logs from one place, then collect outputs such as generated files, model artifacts, or job results.
Instead of opening GPU dashboards, comparing instance types, and building retry logic, you submit the workload and monitor it from Jungle Grid.
Demos
See a real AI workload run from an Activepieces workflow through Jungle Grid Ready Paths — from trigger to completed result in 31 seconds, without manually provisioning or selecting GPUs.
A straight operator flow in the terminal: describe the workload, submit by intent, and let Jungle Grid place the run on compatible GPU capacity.
A Claude-driven workflow where a natural-language workload request becomes a real GPU-backed execution path through Jungle Grid.